The Role of Big Data in Training OpenAI's Language Models
Unlock your data potential with OpenAI's language models #Bigdata #OpenAI #DataSeries
DATASERIESOPENAIBIGDATA
Liam N.
11/12/20232 min read
Welcome to the fascinating intersection of Big Data and AI, where the voluminous and varied data sets breathe life into AI models like GPT-4. Let's explore how Big Data shapes the capabilities of these advanced language models.
Understanding Big Data in AI-Language Training
Big Data refers to extremely large data sets that are analyzed computationally to reveal patterns, trends, and associations, especially relating to human behavior and interactions. In the context of AI language models like OpenAI's GPT-4, Big Data is indispensable.
Key Points:
Diverse Language Examples: Big Data encompasses a wide array of text sources – from books and articles to websites and social media posts. This diversity exposes the AI to various linguistic styles, contexts, and nuances, making it adept at understanding and generating human-like text.
Volume and Variety: The sheer volume of data ensures that the model encounters numerous instances of language use, while the variety encompasses different languages, dialects, slangs, and writing styles. This extensive exposure helps the model to generalize better and respond accurately in various scenarios.
Best Practices in Utilizing Big Data for Language Models
Data Diversity: Ensure the dataset includes a broad range of languages and dialects, as well as different writing styles – from formal to colloquial. This diversity is crucial for creating a well-rounded model.
Regular Updates: Language evolves, and so should the dataset. Regular updates help the model stay relevant to current language usage and trends.
Ethical Considerations: It's vital to consider privacy and consent in data sourcing. Strive to use ethically sourced data to avoid privacy violations.
Simple Coding Example: Data Preprocessing
While I can’t show you the exact process OpenAI uses (as their training methods and data are proprietary and not publicly available), I can give you an idea of how data might be preprocessed for a language model.
Scenario: Preprocessing Text Data for Training
Let's say we're preparing a dataset of English sentences for training a simple language model. Our goals are to clean and standardize the data.
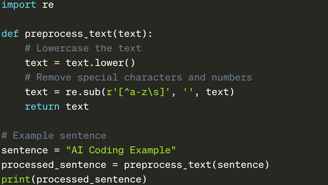
Coding Example:
In this basic Python example, we perform two preprocessing steps: converting text to lowercase and removing special characters and numbers. These steps help standardize the data, making it easier for a language model to learn from it.
In the vast and intricate landscape of AI language training, Big Data is the bedrock. It's the diverse and extensive data that teaches language models not just to understand and replicate human language but to do so with an understanding of its richness and variability. Remember, in the world of AI, data is not just king; it's the teacher, guide, and path to linguistic intelligence.
Made with <3 from SF